Control Limits for Attribute SPC Charts
Control limits are located 3 standard deviations above and below the center line. Data points outside the limits are indicative of an out-of-control process.
Recall, just because points are within the limits does not always indicate the process is in control.
These charts can and should be done by manually by hand in the early stages. Statistical software can be used once the formulas and meaning are understood. Any data point(s) that statistical software recognizes as failing (the common cause variation test) means there is likely a nonrandom pattern in the process and should be investigated as special cause variation before proceeding with a capability analysis.
There are numerous tests that used to detect "out of control" variation such as the Nelson tests and Western Electric tests.
What if the LCL is calculated to be <0?
This situation is not uncommon. In this case, the LCL is assigned to be 0 and there is only an UCL.
What if I'm able to assign cause to points that appear to be out-of-control?
If you have assignable cause to points that appear to make your chart out-of-control you can eliminate them from the UCL and LCL calculation. Keep in mind, this means you'll need to recalculate the centerline value too as part of the revised UCL and LCL.
Doing this is known as calculating Revised Control Limits.
If you had 30 samples and 2 of them were out-of-control but you were able to assign cause to them, then you rerun your UCL and LCL calculation with the data just from the 28 remaining samples.
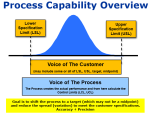
In control doesn't necessarily mean a happy customer!
Remember that even though a process may be in-control, that does NOT mean that the process is meeting the expectations from the customer. It only means the process is consistent.
The customer expectations are provided as the specifications. The customer specifications are the LSL and USL and sometimes they will provide a target (that isn't always in the middle of the LSL and USL).
For the process to be in-control AND meeting the customer specifications, the process control limits should be within the customer specification limits (or a least the amount which customer wants acceptable parts).
Attribute and Variable Data
Several other non-Shewhart based control charts exist and most statistical software programs have these options.
The EWMA is one method that is commonly used for detecting smaller shifts quickly, less than or equal to 1.5 standard deviations. The data is also based on a normal distribution (same a I-MR and X-bar & R) but the process mean is not necessary a constant.
EWMA - Exponentially Weighted Moving Average
SPC Implementation
Most processes should benefit from SPC Charts whether it's for continuous or discrete data. Following these basic ground rules will ensure your customers will benefit, your audit scores will improve, your quality levels will improve, and a more stable business overall. These are some of the leading indicators to long term profitability.
DO:
- Most importantly, determine which process characteristics to control.
- Choose a small area to begin the implementation.
- Train personnel in SPC, especially those not familiar with the terms and most of all, the operators and those using the chart and performing calculations.
- Train on how to react to certain conditions and perform corrective action.
- Determine the proper type of chart(s) to use.
- Start by manually charting data and performing the calculations on paper.
- Appoint a person responsible for the program and maintenance.
- Supervisors, managers, leadership need to be prepared to address and attend issues and make it a primary role in their job.
- Set SMART goals to achieve new quality levels.
- Use the charts for purpose and avoid playing with the numbers and showing off the charts for customers or upper leadership reviews.
- Once key stakeholders under that calculations on paper, decide on software for the long term.
- Use SPC for process monitoring & live feeds to help reduce process variability.
DON'T:
- Avoid implementing everywhere at one time. Build confidence in the system by showing that it can be done....and done effectively with results.
- Refrain from using software at the beginning. Learn first by doing it manually.
- Abort the program when encounters a roadblock, resistance or tough decisions.
- Expect that changes will be drastic and immediate. Part of the process is developing baseline data that takes time to generate.
- Just implement on the manufacturing floor. Try to implement SPC where other things are measured such as on-time delivery.
- Avoid slogans. Make the results visual and update them regularly as they pertain to the SPC program.
Templates, Tables, and Calculators
Project Acceleration Techniques
Return to Six-Sigma-Material Home Page
Recent Articles
-
Process Capability Indices
Oct 18, 21 09:32 AM
 Determing the process capability indices, Pp, Ppk, Cp, Cpk, Cpm
Determing the process capability indices, Pp, Ppk, Cp, Cpk, Cpm -
Six Sigma Calculator, Statistics Tables, and Six Sigma Templates
Sep 14, 21 09:19 AM
 Six Sigma Calculators, Statistics Tables, and Six Sigma Templates to make your job easier as a Six Sigma Project Manager
Six Sigma Calculators, Statistics Tables, and Six Sigma Templates to make your job easier as a Six Sigma Project Manager -
Six Sigma Templates, Statistics Tables, and Six Sigma Calculators
Aug 16, 21 01:25 PM
Six Sigma Templates, Tables, and Calculators. MTBF, MTTR, A3, EOQ, 5S, 5 WHY, DPMO, FMEA, SIPOC, RTY, DMAIC Contract, OEE, Value Stream Map, Pugh Matrix



Site Membership
Click for a Password
to access entire site
Six Sigma
Templates & Calculators

Six Sigma Modules
The following are available
Click Here
Green Belt Program (1,000+ Slides)
Basic Statistics
Cost of Quality
SPC
Process Mapping
Capability Studies
MSA
Cause & Effect Matrix
FMEA
Multivariate Analysis
Central Limit Theorem
Confidence Intervals
Hypothesis Testing
T Tests
1-Way ANOVA
Chi-Square
Correlation and Regression
Control Plan
Kaizen
MTBF and MTTR
Project Pitfalls
Error Proofing
Effective Meetings
OEE
Takt Time
Line Balancing
Practice Exam
... and more